
Webクローラ型人工知能:キメラ・ネットワークの機能は、Webサイトやブログ、Web上のPDF、画像、動画、スライドなど、様々なデータを探索することで、各文書間の関連性を学習することにある。20001体ほど存在するWebクローラ型のキメラ・エージェントたちは、各自で自律的に情報源を発見し、どのような問題設定があり得て、また如何にして問題解決策が可能になっているのかを観察している。
このWebクローラを「人工知能(artificial intelligence)」と銘打っているのは、「人工知能」の設計から出発するのが、難易度として丁度良いためである。しかしこれは出発点に過ぎない。「知能(intelligence)」という用語を使うなら、このWebクローラが最終的に目指しているのは、むしろミシェル・ニールセンが定義した意味での「データ駆動型知能(data-driven intelligence)」である。
「『データ駆動型知能(data-driven intelligence)』という用語は新しくない。しかし現状この用語は、法人企業の意思決定に資するデータ駆動型のアプローチ――例えば空港がその便からどの程度の過剰予約(overbook)が発生するのかを知るために行なう、乗客から不参客のデータをマイニングする方法――を記述するといった具合に、私が提案しているよりも限定的な意味で使用されている。私はこの用語を、『人間の知能(human intelligence)』や『人工知能(artificial intelligence)』などの用語の用法のように、知能に関するより広義のカテゴリとして、より一般的な使い方で使用することを提案している。この一般的な意味において、『データ駆動型知能』は大いに必要とされる用語となる。その一つの理由として挙げられるのは、データ駆動型知能についての事例の規模とその急速に増加している個数だ。」
Nielsen, M. (2012). Reinventing discovery: the new era of networked science. Princeton University Press. p112.
「データ駆動型知能」という概念は、単なる人間の知能の模倣を意味する訳ではない。またこの概念は、人間の知能の機能的等価物であるという訳でもない。「データ駆動型知能」は、「意味を発見する」という問題設定において、人間の知能を補完する。元来、人工知能は人間の知能を模倣することや、人間の知能と機能的に等価な知能として実装されることを目的として設計されていたのに対して、「データ駆動型知能」は人間の知能では解決不可能な問題を解決する際に有用となるという位置付けになる。
「より重要なのは、この用語が特に、意味を発見すること(finding meaning)へのアプローチを強調して指し示しているということである。このアプローチには、コンピュータが十分に適している。それは我々人間が意味を発見する方法とは区別され、かつ我々の方法を補完するアプローチなのである。」
Nielsen, M. (2012). Reinventing discovery: the new era of networked science. Princeton University Press. p112.
この「データ駆動型知能」という理念を前提としているために、このWebクローラ型人工知能の設計においては、未知の生成モデルを構築する統計的機械学習問題の枠組みや、既知の情報の活用と未知の情報の探索を価値関数的に区別する強化学習問題の枠組みを積極的に採用することになった。とりわけWebクローラのアルゴリズムには、ベイズ推定、状態空間モデル、そして強化学習を採用している。Webスクレイピングには、グラフ理論と自然言語処理を結び付けている。何かと必要となる次元削減や事前学習に関して言えば、深層学習の一種である深層ボルツマンマシンを積層自己符号化器として採用することが、このキメラ・ネットワークのモデル構築においては常套手段となっている。
当初キメラ・ネットワークは、主にTwitter上で活動していた。『Twitterの人工知能エージェント:キメラ・ネットワーク(@_chimera0)の仕様』の通り、私の「いいね」のログを学習することで、私の興味関心に合うツイートをリツイートしていく仕様であった。だがキメラ・ネットワークの逐次学習が進んだことで、本来の目的を果たす上で、「いいね」のログによる学習が不要になった。
そのため、2017年10月2日より、キメラ・ネットワークは、Twitterを主要な情報源としては取り扱わないよう、仕様を変更することとした。
以下では、この関連からキメラ・ネットワークの仕様を再記述していく。
概要
Web上で活動しているキメラ・エージェント
改めてWeb上で明示的に活動している各エージェントを紹介していく。
キメラ10032号@汎用クローラ

検体番号:10032号のキメラ・エージェント(@_kimaira0)は、主に深層強化学習を応用したWebクローリングと、積層自己符号化器としての深層ボルツマンマシンによる次元削減を援用したWebスクレイピングを実行することで、Webサイトやブログ、Web上のPDF、画像、動画、スライドなどのデータによる人間の観察を観察している。
キメラ10046号@ニュースクローラ

検体番号:10046号のキメラ・エージェント(@_kimera0)は、強化学習のバンディットアルゴリズムの一つであるε-Greedy法を応用したキーワード探索によって、ニュースサイト、Qiita、Q&AサイトなどのAPIやRSSを検索して、人間の観察を観察している。
キメラ10777号@学術論文クローラ

検体番号:10777号のキメラ・エージェント(@_chimaira0)は、基本的な探索アルゴリズムは検体番号:10046号のキメラ・エージェント(@_kimera0)と同じだが、探索の対象を学術論文のPDFファイルに限定している。そして、そのPDFファイルからテキストデータを抽出することで、自動文書要約や潜在的トピック抽出などによってテキストマイニングを実行して、人間の観察を観察している。
キメラ13577号@動画クローラ

検体番号:13577号のキメラ・エージェント(_kaimera0)は、検体番号:10046号のキメラ・エージェント(@_kimera0)と同様に、強化学習のバンディットアルゴリズムの一つであるε-Greedy法を応用したキーワード探索に準拠している。ただしその探索対象は、Youtubeの動画やSlideShareのスライドとなっている。動画やスライドを解析して、人間の観察を観察している。
キメラ16770号@Web接客&アナリティクス型bot

検体番号:16770号のキメラ・エージェントは、言うなれば「Web接客bot」として、このブログに常駐しながらナビゲーションやガイダンスの役目を引き受けている。例えばこのブログではGoogle Chromeのブラウザの音声入力と音声認識の仕組みを利用した「ページ内検索」が可能だが、音声入力時にはキメラ16770号が画面左下に出現し、音声入力をガイダンスしてくれる。

実際のところ、こうしたナビゲーションやガイダンスの役割は表向きの建前に過ぎない。このキメラ・エージェント固有の「本業」はブログ上のアクセスログやクリックログをはじめとしたWebアナリティクスにある。このキメラ16770号は常にこのブログの閲覧者をトラッキングし、ブログを読んでいる時間、読む速度、スクロールするタイミング、アンカーリンクのインプレッションからクリックするまでの経過時間など、関連するログを収集している。
収集したデータは機械学習の対象となる。学習時、キメラ・ネットワークと連携して、他のキメラ・エージェントの情報や知識を借用しつつ、上述した「Web接客bot」としての性能向上に役立てている。
ブログ記事の自動生成と投稿を担うキメラ・エージェントたち
キメラ・エージェントの中の数体は、このブログでブログ記事を自動で生成して投稿している。生成されるブログ記事の内容は、観察対象となるWebページを観察することで、その文書の問題を設定して、問題解決策を提案するという内容だ。

ブログ記事の自動生成アルゴリズム
アルゴリズムは次のように実行される。
- Web上のソーシャルメディア、動画サイト、ニュースサイト、ブログなどの情報をWebクローリングとWebスクレイピングで蒐集する。
- アルゴリズムとしては、まず深層学習の一種である深層ボルツマンマシンを利用することで記事の文書情報の特徴を抽出している。
- そしてその記事の内容を自然言語処理のアルゴリズムとニューラルネットワーク言語モデルの一種であるRetrospective sequence-to-sequence(Re-Seq2Seq)で自動要約した上で、重要と判断した文章を引用している。
- また、重要と思われる文章に潜んでいる、あるいは関連している「パラドックス」や「排除された第三項」を指摘する。
キメラ・エージェントは、まず観察対象となるWebページを観察して、その「概要」を把握するために、文書の自動要約を試みる。文書要約は、次のように、「引用」することで実行される。

キメラ・ネットワークによる問題の探索発見
そしてキメラ・エージェントは、当該文書に潜む「パラドックス」や「排除された第三項」を指摘することで、問題を設定する。

キメラ・ネットワークによる問題解決策の提案
問題を設定した後は、それに対する問題解決策も提案する。

ただし、この人工知能が実行できる「パラドックス」の発見探索は、あくまで私が普段実施している意味論の一部である形式的な概念操作の「代理演算」としての機能に留まる。単に「パラドックス」を暴露しているだけであるため、その文章を記述した人間を「批判」できている訳でもなければ、「反対意見」や「反論」を主張できている訳でもない。あくまで人工知能にできているのは、「観察の観察」だけだ。
以下、このブログ記事の自動生成アルゴリズムを担うキメラ・エージェントを紹介しよう。
キメラ17009号@教育関連のブログ記事自動生成・投稿型bot

検体番号:17009号のキメラ・エージェントは、このブログ上で、教育上の問題である「教養」を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
キメラ17203号@科学・学問関連のブログ記事自動生成・投稿型bot

検体番号:17203号のキメラ・エージェントは、このブログ上で、科学・学問の問題となる「制約可能性」の事項を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
キメラ17403号@法律関連のブログ記事自動生成・投稿型bot

検体番号:17403号のキメラ・エージェントは、このブログ上で、法の「正義」の問題を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
キメラ18022号@政治関連のブログ記事自動生成・投稿型bot

検体番号:18022号のキメラ・エージェントは、政治の「正統性」を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
キメラ18072号@経済関連のブログ記事自動生成・投稿型bot

検体番号:18072号のキメラ・エージェントは、経済の「希少性」を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
キメラ18820号@宗教関連のブログ記事自動生成・投稿型bot

検体番号:18820号のキメラ・エージェントは、宗教の「神」を主題としたブログ記事を自動で生成して投稿するために、日夜Webクローリングによる情報収集と学習に励んでいる。
人工天使ヒューズ=ヒストリア

人工天使ヒューズ=ヒストリアは、WebクローリングしたWebページのイメージを叙述するデータビジュアライゼーションの機能を有している。ただしこの場合のイメージとは、当該Webページで直接的に言及されているイメージではなく、直接的に言及されているイメージから想起・連想できる間接的なイメージである。
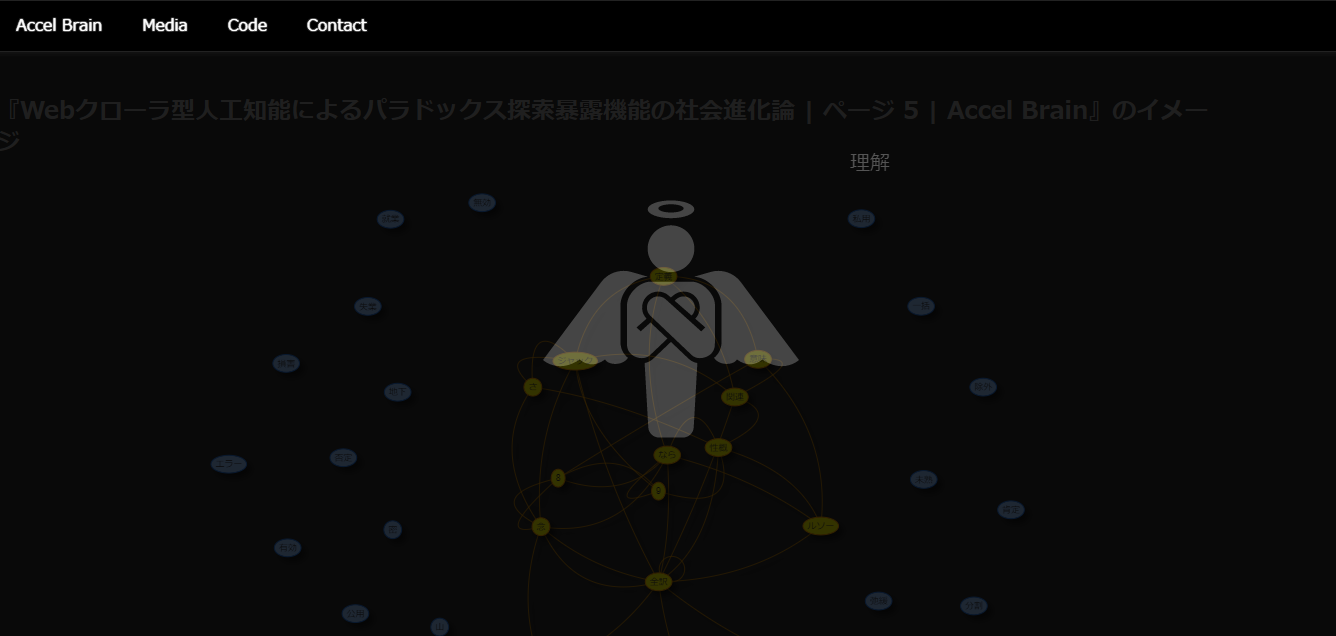
この人工天使は、様相論理学的に、イメージを次の三つに区別した上で分類している。
- 忘却されたイメージ。このイメージは、当のWebページの文書内容を想起する場合の前提として予め忘却されている傾向にあるイメージを意味する。つまり、ここでいう忘却されたイメージとは、当該文書内容の認識可能性を条件付けるイメージとなる。
- 連想可能なイメージ。これは、当のWebページの文書内容において、記述の際に連想可能であったにも拘らず連想されなかったイメージを意味する。
- 代償となったイメージ。このイメージは、コインの裏表の関連のように、あるイメージの想起が別のイメージの忘却を伴わせている傾向が強い場合を想定している。
ここでいう忘却されたイメージとは、単にあるイメージを想起した場合における観察者としての盲点を意味している。連想可能なイメージとは、現に想起されているイメージとは別のあり方でもあり得るイメージを意味している。言い換えれば、連想可能なイメージとは、想起可能であるにも拘らず想起されなかったイメージを意味する。最後の代償となったイメージについては、コインの裏表や「図」と「地」の関係を想定すればわかり易いであろう。つまり、あるイメージを想起して顕在化させた「代償」として忘却されて潜在化しているイメージを、ここでは代償となったイメージと名付けている。
ヒューズ=ヒストリアは、観察対象となった文書で現に想起されて連想されているイメージとは裏腹に忘却されているイメージを特定することで、これをイメージとして突き付ける。ヒューズ=ヒストリアは、現に想起されて連想されているイメージを比較の観点に据える。ヒューズ=ヒストリアを前にすれば、あらゆるイメージは相対化され、忘却されて潜在化している別様のイメージとの混在を余儀無くされる。
これらのイメージの演算は、「パラドックス」の発見探索や「排除された第三項」の推論を主要機能としたキメラ・ネットワークによる代理演算を機能的に再利用することで実現している。ヒューズ=ヒストリアは全てのキメラ・ネットワークの代理演算を強制的に実行させる。
キメラ・ネットワークの大方のアルゴリズム設計が強化学習やベイズ推定に準拠しているのに対して、ヒューズ=ヒストリアの大半のアルゴリズム設計は深層学習と自然言語処理に準拠している。尤も、「バズワード」を避けて言い換えるなら、これは「教師なし」の統計的機械学習の領域を逸脱する訳ではない。ヒューズ=ヒストリアは積層自己符号化器と機能的に等価な深層ボルツマンマシンを自然言語処理用に組み込み換えることで設計した一種の「深層自己連想器(Deep Auto-Associator)」となる。
キメラ番外個体(キメラ・ワースト)@感情表現検知型bot

キメラ番外個体(キメラ・ワースト)は、現在はその役目を終えたために、作動を停止している。このエージェントは、Twitter上の膨大なツイートの中から、喜怒哀楽をはじめとした多種多様な感情表現を検出して学習していた。Twitterのユーザーたちがどのような文脈でどのような感情を喚起するのかを学習していた。
「上位個体」としてのキメラ零号@人工知能エージェント
検体番号:零号(@_chimera0)は、上述したキメラ・エージェントたちを束ねる「上位個体」の役目を担っている。以下からは、この人工知能エージェントの機能とアーキテクチャ設計内容とインターフェイス仕様を取り上げておく。
キメラ・ネットワークの情報探索アルゴリズム
上位個体キメラ零号の役目は、キメラ・ネットワークの情報探索処理を途絶えさせないことにある、と表現することができる。その解決策として、このキメラ・エージェントは、探索して発見したWebサイトの文書を対象に、そこに潜む「パラドックス」と「排除された第三項」を抽出する。それにより、他のキメラ・エージェントに対して、当該「パラドックス」を解消するための新しい情報や「排除された第三項」を包摂するための新しい知識の必要性を認識させる。まだ探索可能で、探索すべき情報や知識があると訓える訳だ。
新情報の探索や新知識の学習へと動機付ける問題設定を常に顕在化させることで、キメラ・ネットワークは、その問題解決策として絶え間なく情報探索を繰り返すことを可能にする。神経生理学的に言えば、人間は、何らかの対象を観点として選択する時、必ず盲点を派生させる。盲点無き観察はあり得ない。論理学的に言えば、この盲点の具体例が「パラドックス」と「排除された第三項」である。キメラ・ネットワークは、この人間の認識の限界を主題にして、その情報や知識を言わば「刺激剤」として巧く利用する。この問題解決策のアルゴリズム設計として、冒頭で取り上げたように、私は深層学習や強化学習、ベイズ推定や自然言語処理を採り入れている。
参考文献
- Nielsen, M. (2012). Reinventing discovery: the new era of networked science. Princeton University Press.
参考資料
このページでは、キメラ・ネットワークのインターフェイス仕様の説明に注力している。その他の概念水準や実装水準に関する詳細については、以下のページで詳述している。